Our intern created this PDF generator. It's not 100% secure yet, but there's nothing valuable on this host anyway.
Website: http://pdfcarnage.rumble.host/

The content of the Website looks rather simple and so is its purpose. You can submit a query and it redirects you to a pdf where the input and the user-agent of the browser is reflected.

We can download the pdf and check if anything seems odd. What about strings? Hidden Text or anything else?
But after a while I came to the conclusion that this will not lead to anything useful.
Except the creator of the pdf. This might give a hint about the program running in the background. I checked this by opening dev tools in the browser and inspecting the console:

wkhtmltopdf? Never heared of it. Searching github I found its repository: https://github.com/wkhtmltopdf/wkhtmltopdf
Checked the version for vulnerabilitys and took a look at some security reports where I found a link to an interesting Blogpost about XSS that could lead to SSRF and further exploitation. https://cyber-guy.gitbook.io/cyber-guys-blog/blogs/initial-access-via-pdf-file-silently
Yeah, dont want to read everything in detail now, I wanna try this by myself...
So first lets put in a basic XSS command to check wether this is a thing or not.

Not so cool...
After trying several different methods to gain xss I realized that this is not gonna happen and my input will always be detected as dangerous, no workaround for the filter...
But my input isnt the only thing that gets reflected in the pdf, so what about the user agent?
Setting my user-agent to:

So far so good, but imbedding pictures wont help to crush this challenge. What about webhooks? Works, but wont get us further either...
What about internal files? Trying a few scripts I came up with:

There were a few files accesible, but not all of them were interesting or usefull for this challenge
But lets take a look at

Two private network addresses, one for the flask application and one for an nodeApi?
Can we access these somehow within the pdf creation? So, flask usually runs on port 5000, lets check!
This will create an pdf, however its empty. So the port seems to be the right one, but no more information besides that. Tinkering with that for a while I found nothing...
So I took a closer look at the api, accessable on

Yeah, no shit Sherlock, I already knew you were the API.
Okay lets check some endpoints here. Maybe
So there are two options now to solve the challenge:
The real Problem at the end was that requesting a PDF had a limitation of 15 requests per minute. Maybe this writeup reads like "I know about dynamic pdf XSS, let me grab the flag real quick", but it was not. Finding out LFI works was a matter of under 30min. Finding the flag? Whole different story.
Time ran out, and either you were lucky enough to check for
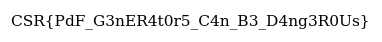
The challenge was overall pretty cool. Fuzzing limitaiton was pain in the ass

Comming Soon I guess
Just a S0l0N00b crushing some easy WebChallenges